الفصل العاشر
Elementary
Data Structures
هياكل
البيانات البدائية
مقدمة
في
الفصل ده بإذن الله هنتعرض لأبسط
Data
structure, ولكن
في الحقيقة فهم الـ Data
structures البسيطة
دي بيساعد في فهم مواضيع كتير في الـ
Computer
science بشكل
عام,
لإن
الـ Data
structures اللي
هنشوفها في الفصل ده بتستخدم في Problems
كتير
جدا.
في
الفصل ده هنشوف 4
هياكل
بيانات:
- Stack.
- Queue.
- Linked List.
- Rooted Tree.
Stack
أحنا
اتعرضنا في الفصل السادس لل Heap
وقلنا
ان معنى كلمة Heap
هي
كومة
(شوية
حاجات مرمين فوق بعض بشكل
غير منظم),
كلمة
Stack
بقى
معنى كومة (شوية
حاجات فوق بعض ولكن بشكل
منظم),
والطبيعي
جدا لو عندك مجموعة عناصر فوق بعض ومعاك
عنصر جديد أسهل مكان تحط فيه العنصر الجديد
هو من فوق,
وكمان
لو هتاخد عنصر من العناصر دي أسهل عنصر
تاخده هو العنصر اللي من فوق
خالص (اللي
هو اخر عنصر انت حطيته في الـ Stack),
وهي
دي الـ Stack:
عبارة
عن Data
structure بتوفر
عمليتين:
- Push.
- Pop.
عملية
الـ Push
هي
بتاخد عنصر وتحطه فوق الـ Stack,
وعملية
الـ Pop
بتجبلك
اخر عنصر اتحط في الـ Stack,
علشان
كدة بيسموها Last
In First Out أو
اختصارا LIFO
يعني
اخر عنصر تحطه هو أول عنصر تاخده.
بالنسبة
لواحد أول مرة يتعرض لل Stack
هيكون
الموضوع بالنسباله غريب,
وهيسأل:
هو
إيه الـ Data
اللي
انا ممكن أحتاج أخزنها في حاجة زي كدة؟
الإجابة:
كتير.
مع
إن الـ Stack
بسيطة
جدا إلا إن فيه Problems
كتير
بتتحل بيها,
كمثال
بسيط:
وانت
بتتعامل مع الـ web,
بتتحرك
ما بين الصفحات,
هنا
احنا محتاجين نخزن الصفحات اللي انت
بتتصفحها,
طبيعة
التخزين هنا محتاجة Stack
لانك
لما بتحتاج ترجع خطوة بترجع لاخر صفحة
انت كنت فاتحها (Last
In First Out), اخر
صفحة انت دخلتها (Last
in) هي
أول صفحة انت بتحتاجها (First
out).
علشان
نمثل الـ Stack
إحنا
محتاجين:
- الـ Array اللي هنخزن فيها العناصر.
- أي حاجة تشاور على اخر مكان واقفين عنده(المكان اللي نقدر نعمل منه Pop) وهنسميه top[s] وقيمته بداية بتكون 0 (في حالة الـ one-index based أما في الـ programming قيمته بداية بتكون ب -1 في معظم اللغات الـ zero-index based).
- عمليتين الـ Push وال Pop.
طبعا
الـ Stack
بيكون
ليها Size
محدد,
فلما
تيجي تعمل Push
ممكن
يكون الـ Stack
مفهش
مساحة وبالتالي تحصل مشكلة بنسميها
Overflow,
ولما
تيجي تعمل Pop
ممكن
تكون الـ Stack
مفهاش
عناصر أصلا وبالتالي تحصل مشكلة بنسميها
Underflow.
نشوف
بقى ازاي ممكن نمثل الـ Stack
ك
Pseudocode.

- أول Algorithm هو Stack_Empty وده بي check إذا كان الـ Stack فاضي ولا فيه عناصر, وطبعا الـ Stack بيكون empty لما يكون top[s] (اللي بيشاور على اخر عنصر حصله Push في ال Stack) بيساوي صفر.
- تاني Algorithm هو عملية الـ Push وده بيزود الـ top[s] ب 1 وبعدين يحط العنصر الجديد في المكان اللي بيشاور عليه top[s]. لاحظ انه هنا مش بي check الـ Overflow ولكن في أي code تكتبه انت المفروض انك ت check.
- تالت Algorithm هو عملية الـ Pop وده بي check في الاول لو الـ Stack فاضية يبقى Underflow لو مش فاضية بيقلل الـ top[s] ب 1 علشان يشاور على العنصر اللي قبل العنصر اللي هنعمله Pop وبعدين يرجع العنصر اللي بيشاور عليه top[s] + 1 (العنصر اللي كان بيشاور عليه قبل منقلله).
والشكل
ده بيوضح العمليات اللي بتحصل على الـ
Stack.

في
(a)
بيوريك
العناصر الموجودة في الـ Stack
وهما
عددهم 4
وبالتالي
top[s] =
4 , وفي
(b)
بيوريك
عملية الـ Push
مرتين
للعناصر 17
وبعدين
3 , وفي
(c)
بيوريك
عملية الـ Pop.
وده
implementation
لل
Stack
بلغة
الـ C.
Queue
كلمة
Queue
يعني
طابور,
وأي
طابور ليه بداية
هنسميها Head
(رأس)
ونهاية
هنسميها Tail
(ذيل),
الطبيعي
جدا لما يجي حد جديد بيقف في نهاية الطابور
عند الـ Tail
ولما
نيجي ناخد حد من الطابور علشان ياخد الخدمة
اللي مستنيها بناخد اللي في الـ Head
(أول
واحد دخل الطابور),
,وهي
دي الـ Queue:
عبارة
عن Data
structure بتوفر
عمليتين:
- Enqueue.
- Dequeue.
عملية
الـ Enqueue
بتضيف
عنصر عند الـ Tail
وعمليى
الـ Dequeue
بتاخد
العنصر اللي عند الـ Head
, علشان
كدة الـ Queue
بنسميها
First
In First Out أو
اختصارا FIFO
(أول
واحد يدخل هو أول واحد يخرج),
طبعا
الـ Queue
بتستخدم
في Problems
كتير
جدا,
كمثال
بسيط:
أي
Server
بيجيله
requests
من
الـ Clients
علشان
يأديلهم خدمة محددة,
من
الـ algorithms
المشهورة
في تنظيم عملية الـ Scheduling
للـ
requests
دي
(مين
ياخد الخدمة قبل مين)
algorithm إسمه
First
Come
First
Serve
يعني
اللي ييجي الأول ياخد الخدمة الأول,
وده
واضح جدا انه ممكن يتنفذ بال Queue.
علشان
نمثل الـ Queue
إحنا
محتاجين:
- الـ Array اللي هنخزن فيها العناصر وليها Size محدد بنرمزله Length[Q].
- أي حاجة تشاور على الـ Head بنرمزلها Head[Q] وحاجة تاني تشاور على الـ Tail بنرمزلها Tail[Q] , بداية بنخلي قيمتهم واحدة وده معناه إن الـ Queue مفهاش عناصر لسة. في الـ implementation اللي هنشوفه الـ Head بيشاور على أول عنصر دخل في الـ array(المكان اللي انت هتعمله Dequeue مباشرة) ولكن الـ Tail بيشاور على مكان فاضي(المكان اللي هتعمل فيه Enqueue مباشرة).
- عمليتين الـ Enqueue وال Dequeue.
طبعا
الـ Queue
ممكن
يحصل عليها Overflow
أو
Underflow
ولكن
هو هنا بيتجاهلهم.
نشوف
بقى ازاي ممكن نمثل الـ Queue
ك
Pseudocode.

- أول algorithm هو الـ Enqueue بيحط ال عنصر اللي جاله في المكان اللي بيشاور عليه Tail[Q] وبعدين يزود الـ Tail[Q] ب 1 (في حالة ان الـ Tail[Q] قيمته بتساوي الـ Length[Q] فبيخليه يشاور على أول عنصر في الـ Array وبالتالي هو كدة زوده 1 بطريقة circular).
- الـ algorithm التاني هو الـ Dequeue بيخزن العنصر اللي بيشاور عليه Head[Q] وبعدبن يزود الـ Head[Q] بطريقة circular وبعدين يرجع العنصر اللي خزنه(اللي كان بيشاور عليه الـ Head[Q] قبل ميزوده).
والشكل
ده بيوضح العمليات اللي بتحصل على الـ
Queue.

في
(a)
بيوريك
العناصر اللي موجودة في الـ Queue
وعددهم
5. الـ
Head[Q]
بياور
على الغنصر 15
وده
معناه ان العنصر 15
هو
أول عنصر دخل الـ array
مابين
العناصر الموجودة.
وفي
(b)
بيوريك
عملية الـ Enqueue
للعناصر
17 بعدين
3 بعدين
5
بالترتيب
ده ,
وفي
(c)
بيوريك
عملية الـ Dequeue.
وده
implementation
لل
Queue
بلغة
الـ C.
Linked
List
كلمة
linked
معناها
مرتبط أو متصل ,
وبالتالي
Linked
list
معناها
list
متصلة
ببعضها,
طيب
إيه الجديد أي list
متصلة
ببعضها بشكل ما؟ ده صحيح.
الـ
array
مثلا
هي عبارة عن عنوان مكان في الـ memory
متخزن
فيه أول عنصر في الـ array
وباقي
العناصر متخزنة في الأماكن اللي بعد
المكان ده مباشرة,
يعني
الـ array
بتتخزن
في block
من
الـ memory
مش
في أماكن متفرقة,
علشان
كدة الـ array
لازم
تحدد حجمها(عدد
عناصرها)
وانت
بتعمل declaration
علشان
يقدر يحجزلك block
في
الـ memory
على
قد الحجم اللي انت محتاجه.
الـ
linked
list
بقى
عبارة عن مجموعة عناصر متفرقة في الـ
memory كل
عنصر فيه pointer
بيشاور
على عنوان العنصر اللي بعديه علشان كدة
اسمها linked,
بالطريقة
دي الـ linked
list
انت
مش بتحتاج تحددلها حجم وانت بتعرفها لانها
dynamic
, كل
متحتاج تضيف عنصر جديد انت محتاج أي مكان
فاضي في الـ memory
يشيل
العنصر ده وهتشاور عليه من العنصر اللي
قبلبه في الـ list,
أما
الـ array
علشان
لازم تتخزن في block
فاضي
فلازم تحددله مسبقا حجمها قد إيه.
الـ
linked
list
فيه
منها أنواع:
- Singly-linked list.
ودي
list
متصلة
في اتجاه
واحد
(single)
يعني
كل عنصر فيه pointer
بيشاور
على العنصر اللي بعديه
لكن العنصر مفهش أي معلومات عن العنصر
اللي قبله في الـ list.
وفي
الحالة دي بيكون عندي pointer
اسمه
head
بيشاور
على أول عنصر في الـ list
واللي
منه ممكن أوصل لباقي العناصر,
وكل
عنصر (العنصر
في الـ linked
list بنسميه
node)
بيكون
فيه الـ key
و
next وده
الـ pointer
اللي
بيشاور على الـ node
اللي
بعده وأي satellite
data.
- Doubly-linked list.
ودي
list
متصلة
في الاتجاهين
(double)
يعني
كل node
فيها
pointer
بيشاور
على الـ node
اللي
بعده
و pointer
كمان
بيشاور على الـ node
اللي
قبله.
وفي
الحالة دي بيكون عندي head
بيشاور
على أول node
في
الـ list
وكمان
tail
بيشاور
على اخر node
في
الـ list.
وال
node
بيكون
فيها الـ key
و
next
و
previous
ودول
الـ pointers
اللي
بيشاورو على الـ node
اللي
بعد
وال node
اللي
قبل
بالترتيب وأي satellite
data.
[وده
النوع اللي هنستخدمه في توضيح الـ
operations].

- Sorted.
ودي
list
مرتبة
حسب الـ key
يعني
الـ head
بيكون
الـ node
صاحب
أصغر
key
في
الـ list
وال
tail
بيكون
الـ node
صاحب
أكبر
key
في
الـ list.
- Unsorted.
ودي
list غير
مرتبة.
- Circular.
الطبيعي
ان الـ head
بتاع
الـ list
الـ
previous
بتاعه
بيشاور على Null
لان
مفيش حاجة قبله وال tail
بتاع
الـ list
الـ
next
بتاعه
بيشاور على Null
لان
مفيش حاجة بعده,
أما
الـ circular
list
بتكون
عبارة عن ring
(حلقة)
الـ
previous
بتاع
الـ head
بيشاور
على الـ tail
وال
next
بتاع
الـ tail
بيشاور
على الـ head.

نبدأ
نشوف إزاي ممكن ننفذ العمليات المختلفة
زي الـ Search
وال
Insert
وال
Delete
على
الـ Linked
List.
- Searching a linked list.
معانا
key
معين
وعايزين نعرف هل فيه node
في
الـ list
بنفس
الـ key
ولا
لأ, لو
لقينا node
بنفس
الـ key
بنرجع
pointer
ليها
ولو ملقناش بنرجع Null
. الموضوع
بسيط معايا pointer
اسمه
head
بيشاور
على أول node
في
الـ list
وفكل
node فيه
pointer
اسمه
next
بيشاور
على الـ node
اللي
بعديه,
وبالتالي
أقدر أشاور على ال head
ب
pointer
جديد
(علشان
أقدر أحركه بدون ما أغير حاجة في الـ list)
وأبدا
أحرك الـ pointer
الجديد
ده على الـ nodes
بان
كل مرة أساويه بال next
بتاعه
فيشاور على الـ node
اللي
بعده واطلع من الـ loop
دي
في حالة من اتنين:
اما
ان الـ node
بقت
بتشاور على Null
(يعني
انا عديت على الـ list
كلها)
أو
ان الـ key
بيساوي
الـ key
اللي
انا بدور عليه ,
وفي
النهاية ارجع الـ pointer
الجديد
اللي هيكون ليه حالتين:
اما
وقف على الـ node
اللي
ليها نفس الـ key
اللي
بدور عليه أو عدى عال list
كلها
وبقى ب Null
وبالتالي
انا ملقتش أي node
بنفس
الـ key
وفعلا
عايز أرجع Null.

هنا
في السطر الأول بيشاور عال head
ب
pointer
جديد
وفي سطر 2
و
3 بيعدي
على الـ list
كلها
وبيطلع من الـ loop
في
حالة من الحالتين اللي شرحناهم وفي سطر
4 بيرجع
الـ pointer
الجديد
اللي ليه حالتين زي ماقلنا.
علشان
الـ algorithm
ممكن
يعدي على الـ list
كلها
فال running
time
بتاعه
هو O(n)
في
الـ worst
case.
- Inserting into a linked list.
فيه
أكتر من مكان ممكن ت insert
عنصر
جديد فيه:
ممكن
مثلا في بداية
الـ linked
list أو
نهايتها
أو بعد
عنصر
محدد,
هنا
هنشوف إزاي ن insert
عنصر
في بداية الـ list
. معانا
pointer ل
node
وعايزين
ن insert
الـ
node دي
في بداية الـ list
, بداية
الـ list
يعني
الـ head
, هنا انا محتاج انفذ 4 خطوات : أول خطوة اني اخلي ال next بتاع ال node الجديدة يشاور على ال head بتاع ال list وتاني خطوة ان ال previous بتاع ال node لجديدة يشاور عاى null لان مفيش قبله حاجة , تالت خطوة اني اعمل update لل head اخليه يشاور على ال node الجديدة لانها خلاص بقت ال head ولكن قبل الخطوة دي لازم اخلي ال previous بتاع ال head يشاور على ال node الجديدة ده في حالة ان ال head مش بيساور على Null يعني ال list فيها عناصر.

هنا
في السطر الأول بيخلي الـ next
بتاع
الـ node
الجديدة
يشاور على الـ head
, وهنا
متفرقش اذا كان الـ head
ب
Null أو
بقيمة لانه لو بقيمة فانا عايوز اشاور
على الـ head
ولو
ب Null
فانا
عايو أشاور على Null
, في
سطر 2
بيختبر
لو الـ head
مش
ب Null
بيخلي
الـ previous
بتاعه
يشاور على الـ node
الجديدة(سطر
3) , سطر
4 بيخلي
الـ head
بتاع
الـ list
يشاور
على الـ node
الجديدة,
وسطر
5 بيخلي
الـ previous
بتاع
الـ node
الجديدة
يشاور على Null
لانه
الـ head
وبالتالي
مفيش حاجة قبله.
الـ
running
time
هنا
هو O(1)
يعني
constant
لان
كل العمليات بتتنفذ في constant
time ومش
بن loop
على
أي حاجة.
- Deleting from a linked list.
في
عملية الـ delete
معانا
node
معينة
عايزين نحذفها من الـ list
, هنا
معانا الـ node
نفسها
(يعني
pointer
بيشاور
عليها)
مش
الـ key
بتاعها
, لان
لو معانا الـ key
كنا
هنحتاج نعمل search
في
الاول لغاية منوصل لل node
نفسها
علشان نحذفها,
في
العملية دي احنا عايزين نعمل عمليتين:
الاولى
اننا نخلي ال next
بتاع
الـ node
اللي
قبلها يشاور على الـ node
الي
بعدها والتانية اننا نخلي الـ previous
بتاع
الـ node
اللي
بعدها يشاور على الـ node
اللي
قبلها وبكدة نكون شلناها من الـ list
بأمان.

من
سطر 1
ل
3 بينفذ
العملية الأولى:
سطر
1 بيختبر
اذا كان الـ node
اللي
عايزين نحذفها ليها previous
ولا
لأ , لو
ليها بينفذ العملية زي ما وصفنا ,
لو
ملهاش ده معناه ان الـ node
اللي
احنا عايزين نحذفها هي الـ head
بتاع
الـ list
وبالتالي
انا عايز أغير الـ head
اخليه
الـ next
بتاع
الـ node
اللي
هحذفها.
سطر
4 و
5 بينفذ
العملية التانية:
سطر
4 بيختبر
اذا كان الـ node
اللي
عايز احذفها ليها next
ولا
لا , لو
ليها فانا بنفذ العملية زي ما وصفنا ,
لكن
لو ملهاش فده معناه انها كانت الـ tail
بتاع
الـ list
وبالتالي
مش محتاج أعمل حاجة.
الـ
running
time
هنا
هو O(1)
أو
constant
لكن
لو هيجيلي key
مش
node
فهضطر
أعمل search
في
الأول وبالتالي هيكون الـ running
time يعتبر
linear أو
O(n) في
الـ worst
case.
وده
شكل توضيحي بيوضح العمليات بتتنفذ على
linked
list.

الشكل
(a) بيوضح
Linked
list فيها
4 nodes ,
الشكل
(b) بيوضح
عملية insert
ل
node الـ
key
بتاعها
25 ,
والشكل
(c) بيوضح
عملية delete
لل
node
الرابعة
في الـ list
اللي
الـ key
بتاعها
4
وده
implementation
لل
Linked
list باستخدام
لغة الـ C.
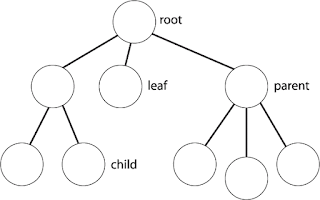
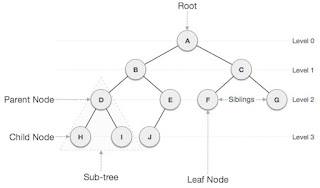
Representing
Rooted Trees
طريقة
representation
الـ
Linked
List
اللي
شفناها حالا (باستخدام
objects و
pointers)
بتستخدم
في representation
لهياكل
بيانات تانية منها الـ Trees
أو
بالأخص الـ Rooted
trees.

الشكل
اللي قدامك عبارة عن Binary
tree
ودي
مش أول مرة نشوفها ,
إحنا
اتعرضنا لل Binary
tree في
الفصل السادس في الـ Mergesort
وعملنا
representation
ليها
باستخدام Array.
الشكل
اللي قدامك عبارة عن مجموعة nodes
متصلة
ببعض عن طريق pointers
, كل
node
عبارة
عن object
فيه
أي data
ومجموعة
pointers
بيربطوه
في الـ Tree
, مجموعة
الـ pointers
دي
بتختلف حسب نوع الـ Tree
مثلا
في الـ Binary
Tree هما
3 بس
لان كل node
ليها
left
child و
right
child و
parent ,
فيه
node الـ
parent
بتاعها
بيساوي Null
ودي
الـ Root
node , وفيه
node الـ
left
child وال
right
child بيساوو
Null ودول
اللي بنسميهم leaves.
بالطريقة
دي نقدر نمثل أي Tree
عدد
الـ children
محدود
(bounded)
ولكن
منقدرش نستخدمها في تمثيل أي Tree
عدد
الـ children
فيها
غير محدود (unbounded)
لإن
أحنا في النهاية لازم يكون عندنا عدد محدد
من الـ children
, كمان
الطريقة دي مبتستخدمش لما يكون عدد الـ
children
كتير
حتى لو كان bounded
, لإن
هننتهي ب nodes
كتير
قيمها ب Null
ود
إهدار لل memory.
في
طريقة تانية إسمها left-child,
right-sibling
representation
ودي
زي ماانت شايف في الشكل ده

عبارة
عن Tree
الـ
node فيها
عبارة عن الـ data
و
3
pointers: الـ
parent
وال
left-child
ودول
عارفينهم ولكن التالت هو الـ right-sibling
وده
بيمثل الـ node
اللي
جنب الـ node
الحالية
وبالتالي كل level
ممكن
يكون فيه عدد unbounded
من
الـ nodes
اخر
node في
الـ level
بيكون
الـ right-sibling
ب
Null.

تعليقات
إرسال تعليق