الفصل الحادي عشر
Hash
Tables
مقدمة
اتعرضنا في الفصل العاشر لأبسط Data Structures وعرفنا ايه هي العمليات اللي بنحتاج ننفذها على ال Data Structures دي اللي هي ال Insertion وال Deletion وال Search . وعرفنا ان أي Data Structure بتنفذ ال 3 عمليات دول بتسمى Dictionary . معظم ال Data Structures مش بتبقى المشكلة في ال Insertion ولا في ال Deletion .. دي عمليات Data Structures كتير ممكن تنفذها في O(1) في ال Worst Case زي مثلا ال Doubly Linked List كمثال . المشكلة دايما في ال Search اللي معظم ال Data Structures بتنفذها في O(n) في ال Worst Case .. النهاردة هنتعرض لل Hash Tables ودي Data Structure بتمكنا من تنفيذ ال Insertion وال Deletion وال Search في O(1) في ال Average(Expected) case وتحت شروط معينة نقدر نوصل ل O(1) في ال Worst Case.
ال Hash Table هو Generalization لفكرة ال Array بس علشان نفهم المعلومة دي كويس عايزين نشوف ال Array بنظرة مختلفة شوية .. مبدأيا ميزة ال Array في ال Direct Addressing .. أو القدرة على اننا ن access عنصر في ال array في O(1) وده بسبب وجود ال indices .. انك لو عارف العنصر اللي انت عايزه ال index بتاعه كام تقدر ت reference العنصر ده بخطوة واحدة .. معنى كدة ان لو معانا داتا عبارة عن records كل record مكون من key و satellite data (لو مش فاهم يعني ايه Key و Satellite Data ارجع لمقدمة الباب الثالث) وال key ده ينفع ك index وفي نفس الوقت عندنا مساحة ل records بعدد ال possible keys دي فهنقدر نخزن الداتا دي في Array ونوصل ل O(1) في ال Worst Case لكل العمليات حتى ال Search وده لان انت بتبحث بال key وبما ان ال Key ده هو ال index فتقدر ت reference ال record ده بخطوة واحدة. يعني كمثال معاك records عبارة عن موظفين وكل record عبارة عن id للموظف وشوية Satellite Data زي اسمه ووظيفته ومرتبه إلخ .. لو ال ids دي بتتراوح مثلا من 0 ل 1000 فاقدر بسهولة احجز (allocate) مساحة من ال Memory ل Array من 1000 عنصر واخزن في كل مكان ال index بتاعه i الموظف اللي ال id بتاعه i يعني الموظف اللي ال id بتاعه 5 هيتخزن في المكان اللي ال index بتاعه 5 .. وبالتالي اقدر ا reference اي record بخطوة واحدة واعمل العملية اللي انا عايزها.
كدة ال array بتقدر توصلنا لل O(1) في كل العمليات في ال Worst Case ايه مشكلتها بقى؟ او ليه مش بنقدر نستخدمها في كل السيناريوهات؟ السبب هو عدم توافر شرط من الشرطين اللي حطناهم فوق في وسط الكلام:
- وال key ده ينفع ك index .
- وفي نفس الوقت عندنا مساحة ل records بعدد ال possible keys دي.
أول شرط مش بالضرورة تكون ال records ال key بتاعها ينفع ك index .. ممكن نكون بنخزن كلمات زي في حالة القاموس مثلا أو أي records ال key بتاعها مش رقم. تاني شرط ان انت علشان ت reference اي عنصر بال key بتاعه محتاج تحجز مكان لكل possible key .. ودي مشكلة؟ طبعا . ال keys مش بالضرورة تكون مرتبة ممكن تكون متباعدة وفي range كبير جدا وال records نفسها قليلة .. يعني مثلا هتخزن مجموعة الطلبة الأوائل في الكلية باستخدام الرقم الأكاديمي ك Key الرقم الأكاديمي بيبقى غالبا مكون من 5 او 6 ارقام زي كدة مثلا 12648 فانت محتاج تحجز array لكل ال range ده اللي هو يوصل ل 100000 في حالة الرقم الاكاديمي مكون من 5 ارقام او 1000000 في حالة 6 ارقام وفي النهاية الطلبة الأوائل عبارة عن 50 يعني 10 لكل دفعة مثلا . في الحالة دي انت ممكن يكون معندكش memory كافية للعدد المهول ده من ال possible keys ولو عندك فدي waste كبيرة جدا.
ال Hash Table بقى فكرتها ببساطة انها بتضيف خطوة بتعمل فيها تحويل من ال Set of possible keys ل Set of array indices .. الخطوة دي بتتنفذ بما يسمى ال Hash function وببتم في constant time . يعني كمثال احنا هنخزن 100 طالب اللي هما الطلبة الأوائل فال Hash function دي هتاخد الرقم الاكاديمي x ترجعلك رقم y قيمته مابين ال 0 وال 100 اللي هما ال array indices بتوعك وال function دي كل ماهتديها الرقم x هترجعلك الرقم y .. وبالتالي اتحلت مشكلة ال memory .. كمان لو ال keys بتاعتك مش ارقام ال Hash function هتاخد ال key وترجعلك رقم ينفع ك index وبالتالي اتحلت مشكلة ان ال keys متنفعش تكون indices. من أشهر التطبيقات لل Hash Table هو ال Symbol table ودي data structure بيستخدمها ال Compiler في تخزين ال identifiers اللي متعرفة في ال software code base وشوية معلومات عن كل identifier .
Direct Address Table
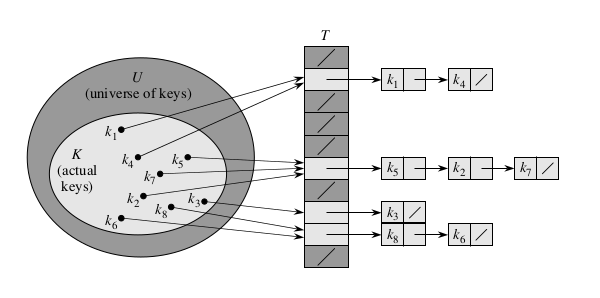
احنا شرجنا يعني ايه Direct Addressing وسط الكلام .. دلوقتي عايزين نعرف ايه هو ال Direct Address Table بشكل رياضي شوية. ال Direct Address Table بنرمزله T هو ببساطة Array بنخزن فيها مجموعة records ال Keys بتاعة ال records دي unique (مفيش 2 records لهم نفس ال key) وجاية من Set of possible keys بنسميها ال Universe وبنرمزلها بالشكل ده
U = [0 .. m-1]
بحيث ان ال Universe ده مش كبير ومش اكبر بكتير من ال Actual number of keys المتخزنة في ال Array وكمان ال keys دي بنستخدها ك Array indices .. اي مكان في ال Direct Address Table بنسميه slot .. الشكل ده بيوضح ال Direct Address Table :

اللي عالشمال ده ال Universe او ال set of possible keys واللي عاليمين ده ال Direct Address Table .. لاحظ ان ال Universe فيه set مسميها actual keys ودي ال keys اللي ليها records متخزنة في ال array .. وفي ال Direct Address Table كل slot ال index بتاعها k اما فيها pointer بيشاور على record ال key بتاعه k وده في حالة ان k موجود في ال actual keys او NIL لو مش موجود.
وبالتالي:
- علشان اعمل Insertion ل record x كل اللي محتاجه اني اعمل assignment لل slot اللي ال index بتاعها key[x] بقيمة x.
DIRECT_ADDRESS_INSERT(T, x)
T[key[x]] ⇽ x
- علشان اعمل Deletion ل record x كل اللي محتاج أعمله اني ا assign ال slot اللي ال key بتاعها key[x] قيمة NIL .
DIRECT_ADDRESS_DELETE(T, x)
T[key[x]] ⇽ NIL
- علشان اعمل Search عن record ال key بتاعه k كل اللي محتاج اعمله اني ا reference ال slot اللي ال key بتاعها k. لو ال record موجود هيرجع لو مش موجود هيرجع NIL.
DIRECT_ADDRESS_SEARCH(T, k)
return T[k]
كل العمليات دي بتتنفذ في O(1) في ال Worst Case.
Hash Tables
لغاية دلوقتي احنا فاهمين ال Hash Table .. بس عايزين نفهمه أكتر. زي ماعرفنا انا ال Hash Table هو ما إلا Array ولكن فيه Hash function وبتعمل map (تحويل) من ال U اللي هي ال Universe او ال Set of possible keys ل Array indices . ممكن نعبر عن ال Hash function رياضيا بالشكل ده:
h: U -> {0, 1, 2, .., m}
وبالتالي انا بقيت بقدر أخزن records ال keys بتاعتها مش بالضرورة تكون تنفع indices وكمان قللت ال storage اللي انا محتاجها من O(|U|) لل O(m) حيث |U| هو ال cardinality of U او عدد العناصر الموجودة في U وده بيكون عدد كبير جدا و m هو عدد العناصر الفعلية اللي انا محتاج اخزنها. وبالتالي بدل مكان العنصر اللي ال key بتاعه k بقى يتخزن في ال slot اللي ال index بتاعها k بقى يتخزن في ال slot اللي ال index بتاعها h(k) يعني ناتج ال hash function مع ال k. الشكل ده بيوضح فكرة ال Hash Table :

كل اللي اتغير هي ال indices من k ل h(k) .
كدة يتبقى مشكلة واحدة وهي هل نقدر نبني Hash function تضمن ان لو اديتها 2 keys مختلفين ترجع 2 hashes مختلفين؟ الحقيقة ده مستحيل .. وده بسبب ان عدد عناصر ال Universe اللي هي |U| اكبر من عدد ال slots اللي هي m فلازم على الاقل اتنين keys من ال U يحصلهم Hashing لنفس ال slot .. وبالتالي لو احنا موفرناش حل للمشكلة دي هنفقد بعض ال keys لان واحد هيعمل override عالتاني وبالتالي التاني ده متخزنش .. الحالة دي بنسميها collision (تصادم) ودي اهم issue في ال Hash table اللي لو اتحلت بشكل efficient هنوصل لل O(1) اللي احنا عايزين نوصله .. وبما ان ال Collision لا يمكن تفاديه فالحل في خطوتين:
- تقليل ال Collision قدر المستطاع وده دور ال Hash function .. وهنتكلم عن ال Hash function بالتفصيل ونشوف أمثلة.
- توفير طريقة للتعامل معاه لما يحصل .. فيه طريقتين مشهورين في التعامل مع ال Collision وهما Chaining وال Open addressing .. هنتعرض لكل طريقة منهم بالتفصيل.
Collision resolution by chaining
كلمة chain يعني سلسلة و chaining يعني التسلسل .. كلمة chaining اول ما بتيجي في دماغي بتخيل ال Linked List لانها زي ماشفنا عبارة عن Chain كل node بتوصلك لل node اللي بعدها من خلال ال next pointer .. وبالتالي طريقة ال chaining في حل مشكلة ال collision هي ما الا انك بدل ماكل slot بتشاور على record هتبقى بتشاور على Head بتاع Linked List وال Head ده يوصلك لباقي ال records اللي موجودة في ال slot دي .. وبالتالي لو عملت Hash ل record في slot فيها record او records مش هيحصل فقد لانهم كلهم هيتخزنوا في نفس ال List . ده بيضيف cost طبعا بسبب ال Operations اللي هتحصل على ال Linked List . الشكل ده بيوضح فكرة ال Chaining :
كل اللي اتغير هو بدل مال slot فيها اما pointer ل record اما NIL بقت اما فيها pointer لل Linked List اما NIL.
نشوف ال 3 عمليات هيبقى شكلهم ازاي:
Insertion
CHAINED-HASH-INSERT(T, x)
insert record x at the head of list T[h(key[x])]
ودي بتتنفذ في O(1) في ال worst case.
Deletion
CHAINED-HASH-DELETE(T, x)
delete record x from the list T[h(key[x])]
ودي بتتنفذ في O(1) في ال worst case في حالة اننا مستخدمين Doubly Linked List لان في حالة ال Doubly Linked List طالما معاك x تقدر ت reference ال next وال previous اما في حالة ال Singly Linked List تقدر ت reference اللي next لكن علشان توصل لل previous محتاج تعدي عال list وده بياخد O(n).
Search
CHAINED-HASH-SEARCH(T, k)
search for record x in the list T[h(k)]
ال search بقى محتاج analysis بالنسبة لل average case لانه بيتوقف على عدد العناصر الموجودة في ال list اللي ال Hash function وصلتنا ليه .. اما في ال worst case فهو linear يعني O(n) لان ال worst case هي ان كل ال keys حصلهم Hashing لنفس ال slot وبالتالي احنا انتهينا ب Linked List عادية .
Analysis of hashing with chaining
دلوقتي عايزين نعمل analysis لل average case لل search في حالة ال chaining. أولا لازم نعمل assumption .. ال Assumption ده هو ما يسمى ال simple uniform hashing ود بيفرض ان اي key ال Hash function بتعمله hashing يكون ليه نفس ال probability انه يروح لاي slot بغض النظر عن ايه اللي موجود في ال Hash table .. ثانيا عايزين نعرف بعض المتغيرات .. أول حاجة m هو عدد ال slots و n هو عدد ال keys اللي متخزنة في ال slots و 𝝰 (ما يسمى ال load factor) هو حاصل قسمة ال n على ال m وده ممكن يساوي واحد او اقل او اكتر من واحد حسب قيم m و n . المتغير 𝝰 هو ال expected number of keys في كل slot وبالتالي ال search في ال average case هيكون O( 𝝰 + 1 ) بسبب اضافة ال hashing . فلو ال 𝝰 ده صغير بمعنى ان n مش اكبر بكتير من m او بمعنى رياضي m = O(n) فال average case هيكون O(1) تحت ال assumption اللي فرضناه.
Hash functions
احنا لغاية دلوقتي فهمنا ال Hash function هتعمل ايه .. هتحول من ال Universe او ال set of possible keys لل array indices .. وكمان هتقلل ال collisions .. بس ازاي تقلل ال collisions؟ او السؤال بشكل أعم إيه المواصفات اللي تخلي ال Hash function كويسة؟ مبدأيا كفاءة ال Hash function في قدرتها على توزيع ال keys على ال slots بشكل منتظم .. يعني لو ال keys عددهم 1000 وال Hash Table ال size بتاعه 500 فأفضل أداء لل Hash function انها توزع 2 على كل slot و 2 ده هو n / m او 𝝰 .. وده بيتحقق لو اتحقق ال assumption اللي فرضناه في ال Analysis of hashing with chaining اللي هو simple uniform hashing .. المسكلة ان ال assumption ده صعب يتحقق بسبب ان ال keys في الغالب مش بيبقى عندنا عنها اي assumption يعني كمثال بتاع الطلبة الأوائل ممكن تكون أرقامهم الأكاديمية قريبة جدا من بعض وممكن تكون متباعدة جدا وهكذا .. في بعض الأحيان بيكون عندنا assumption عن ال keys زي مثلا ان ال keys دي تكون جاية من uniform random generator مابين الصفر والواحد ففي الحالة دي لو ال Hash function بالشكل ده:
h(k) = ⌊km⌋
كدة تقدر تضمن تحقيق ال assumption بسبب ان ال k متوزعة uniformly بال random generator.
من الخصائص اللي مهم جدا تتوفر في ال Hash function هي انها تكون independent على اي pattern موجود في ال data .. بمعنى ان ال hash value متكونش معتمدة على وجود pattern معين في ال data .. علشان الصورة تقرب في ال Symbol table طبيعي ان اسماء ال identifiers في اي program بتكون متقاربة فمينفعش بسبب تقاربهم ده ان ال Hash function تعملهم hashing في نفس الاماكن.
معظم ال Hash functions بتعتمد على ان ال keys جاية من مجموعة الارقام الطبيعية {0, 1, 2, .. } فايه الوضع لو ال keys مش بالشكل ده? لو ال keys مثلا عبارة عن strings زي في حالة ال Symbol table? في الحقيقة دي مشكلة حلها بسيط لان فيه طرق كتير ممكن تحول بيها من strings لارقام .. أبسط حاجة هو استخدام ال Ascii codes بتاعة ال characters اللي متكون منها ال string .. يعني مثلا لو ال key عبارة عن كلمة counter فدي ممكن تكون قيمتها كالتالي:
counter = c(99) + o(111) + u(117) + n(110) + t(116) + e(101) + r(114) = 768
مشكلة الطريقة دي ان اي permutation من نفس الحروف ليه نفس القيمة .. يعني لو فيه key غبارة عن الكلمة دي cuonter بعد تبديل ال o مكان ال u .. قيمتها متغيرتش لان نفس الحروف .. كحل احنا ممكن نستخدم radix يعني الحرف ياخد قيمته مضروبة في رقم حسب مكانه في ال string وال radix اللي استخدمناه .. لو استخدمنا radix مثلا 14 فقيمة الاتنين keys هتبقى بالشكل ده:
counter = c(99 * 140) + o(111 * 141) + u(117 * 142) + n(110 * 143) + t(116 * 144) + e(101 * 145) + r(114 * 146) = 917470009
cuonter = c(99 * 140) + u(117 * 141) + o(111 * 142) + n(110 * 143) + t(116 * 144) + e(101 * 145) + r(114 * 146) = 917468917
هنشوف مثال بسيط ل Hash function.
The division method
طريقة ال Division هي ببساطة لنك بتاخد باقي قسمة ال key على ال m وبالتالي تقدر تضمن ان الخرج هو رقم مابين الصفر وال m .. طبعا ده بعد تحويل ال key لرقم لو هو مش كدة.
h(k) = k mod m
ميزة الطريقة دي انها بسيطة جدا وسريعة جدا .. ومع قيم معينة لل m الطريقة بتكون فعالة في أغلب الحالات .. وبشكل عام اختيار ال m كعدد أولي بيأدي إلى نتائج كويسة .. وده بسبب طبيعة ال mod .. لانك لو اخترت عدد غير أولي بيقبل القسمة على رقم معين فبالتالي كل الأرقام اللي بتقبل ال قسمة على الرقم ده هيحصله Hashing لمجموعة أماكن محددة هي مضاعفات الرقم ده وده هيؤدي إلى نتائج مش كويسة .. بالأخص تجنب أي عدد أس 2 زي 2p لان في الحالة دي هيكون الناتج هو ال p low-order bits بتوع ال key وبالتالي الخرج مبيعتمدش على الرقم كله بيعتمد بس على مجموعة bits منه .. ودي حقايق رياضية.
Universal Hashing
مشكلة ال Hash table ان مهما صممت Hash function كويسة فحتما فيه مجموعة keys يقدروا يخلوا أدائها سئ بأنها تعمل Hashing لل keys في مكان واحد أو مجموعة أماكن قليلة من ال Hash table وبالتالي تخبط في ال Worst case اللي هي Linear يعني O(n) . المشكلة دي شبيهة بمشكلة ال Quick sort لو فاكرين .. ال Quick sort كان سؤيع جدا في ال average case ولكن في ال worst case كان Quadratic يعني O(n2) .. وال worst case دي كانت بتحصل لو الدخل أصلا مرتب أو أقرب إلى الترتيب .. فكنا بنجنب المشكلة دي ازاي؟ كان فيه حاجة بنعملها نخلي ال Quick sort مفيش دخل معين ممكن يضمن انه يوصله لل Worst case؟ الحل كان Randomization .. اننا كنا بنعيد ترتيب الدخل قبل منبعته لل Quick sort algorithm وبالتالي حتى لو الدخل جه مرتب أو أقرب إلى الترتيب فده ميضمنش ان ال algorithm هيقع في ال worst case لان الدخل بيعاد ترتيبه بطريقة Random . الطريقة دي ممكن نستخدمها في حالة ال Hashing .. بس اعادة ترتيب ال keys مش هتفيد لانهم في النهاية هيحصلهم Hashing في نفس المكان .. فالحل اننا يكون عندنا مجموعة Hash functions وبنختار واحدة منهم بشكل random قبل منعمل Hashing وبالتالي مفيش دخل معين يقدر يوقعنا في ال worst case. الطريقة دي إسمها Universal hashing وفيه تعريف رياضي كبير للطريقة دي ولكن اللي قلناه ده هو الفكرة بشكل abstract.
Collision resolution by open addressing
في ال Open addressing مفيش أي storage خارجية .. كل ال items بنخزنها في ال Hash table ومفيش أي Lists .. وبالتالي علشان ميحصلش فقد لازم تكون قيمة ال m أكبر من أو تساوي ال n وبالتالي ال 𝝰 أقل من أو يساوي الواحد . فكرة ال Open addressing اننا هنطور ال Hash function بحيث ان دورها ميكونش بس انها ترجع Hash value لا دي ترجع سلسلة من ال Hash values بحيث ان في حالة ال insertion لو slot فيها item نشوف ال slot اللي بعدها في السلسلة لو فيها item نشوف اللي بعدها لغاية منوصل ل slot فاضية نحط فيها ال item .. طبعا السلسلة دي لازم تكون ثابتة لكل key بحيث ان بالنسبة ال key k بنعدي على نفس السلسلة في ال insertion وال Search . بكدة ال Hash function العادية اللي بنسميها auxiliary hash function بتتحول من الشكل ده:
h: U → {0, 1, .., m - 1}
للشكل ده
h: U x {0, 1, .., m - 1} → {0, 1, .., m - 1}
انها بدل ما كانت بتاخد ال key بس من ال Universe بقت بتاخد ال key وكمان ال probe number اللي بيحدد احنا عايزين رقم كام في السلسلة. طبعا لازم ال probe sequence الناتج من ال Hash function
{h(k, 0), h(k, 1), .., h(k, m - 1)}
يكون عبارة عن permutation من مجموعة ال array indices اللي هي {0, 1, .., m - 1} علشان تقدر تختبر كل ال slots.
بالتالي ال عملية ال Insertion هتبقى بالشكل ده

هنا هو بي loop من 0 ل m - 1 في كل مرة بيعمل Hashing لنفس ال key باستخدام probe number مختلف لحد ميلاقي مكان فاضي NIL يعمل Insert ويرجع ال index ولو ملقيش يرجع error ان ال Hash table مفهش مكان.
بالنسبة لل Search

هنا نفس الكلام بي loop من 0 ل m - 1 في كل مرة لو لقي ال key اللي بيدور عليه يرجعه لو ملقيش اما يكمل لو فيه key مختلف او يرجع NIL لو مفيش أي key وده لان لو ال key اللي بيدور عليه حصله Insert مش هيحصله insert فاي مكان بعيد في ال probe sequence وهو فيه مكان فاضي قريب .. ولو خلص loop وموصلش لحاجة يرجع NIL يعني ال key مش موجود.
المشكلة دلوقتي في ال Deletion .. لان لو عملت Deletion بالشكل الطبيعي انك ت assign ال slot ب NIL هي break ال Search algorithm لانه كان بيعتمد ان طالما فيه NIL يبقى مفيش حاجة بعد كدة في ال probe sequence .. طبعا فيه حلول كتير .. الكاتب ذكر انك ممكن بدل مت assign قيمة NIL ت assign قيمة خاصة ولتكن اسمها DELETED وبالتالي وانت بتعمل Insert هتعامل القيمة دي على انها NIL وتضيف مكانها عادي وال search algorithm هيفضل زي ماهو مش هيتغير .. ولكن المشكلة في الطريقة دي ان ال search time مبقاش يعتمد على ال n بس لان ممكن تفضل تمسح لغاية م n تكون قليلة جدا ولكن في ال search بتلف كتير بسبب وجود قيم كتير DELETED .. فه حل في دماغي انك لما تيجي تعمل Delete تعمل override للعنصر اللي عايز تعمله Delete باخر عنصر موجود في ال probe sequence وتعمل free لاخر عنصر ده بانك ت assign ال slot بتاعته ب NIL.
فاضل دلوقتي نشوف طرق ال probing يعني ازاي بيحصل generation لل sequence .. فيه 3 طرق مشهورين وهما Linear probing و Quadratic probing و Double hashing .. وهنشوف التلاتة ان شاء الله .. قبل منشوفهم عايزين نعرف ان كل مالطريقة تغطي عدد اكبر من ال possible sequences تبقى افضل .. يعني ال possible sequences هي عدد ال permutations بتاع ال Array indices يعني !m في ال best case .. وبالتالي الطريقة اللي بتغطي كل ال range ده تعتبر بتحقق ال uniform hashing assumption اللي هو يعتبر generalization لل simple uniform hashing .. وال assumption ده هو باختصار ان كل ال probe sequences ليهم نفس ال probability بغض النظر عن اللي متخزن في ال Hash table .. طيب ليه ده مهم؟ احنا في ال Hash function العادية كان ال assumption ان ال output بتاع ال function اللي هو ال hash value يكون ليه نفس ال probability انه يكون اي واحد من ال slots وبالتالي التوزيع يكون uniform .. اما دلوقتي ال output بقى sequence مش مجرد value فال assumption طبيعي بيحصله extend انه يغطي ال possible outputs بنفس ال probability علشان يبقى التوزيع uniform.
Linear probing
ال linear probing هو ببساطة انك بتستخدم auxiliary hash function + قيمة ال probe number والناتج باقي القسمة على m بالشكل ده:
h(k, i) = (h`(k) + i) mod m
هنا h` هي ال auxiliary hash function .. بما انا ال sequence بيعتمد على قيمة h`(k) بس فعدد ال possible sequences هو m وبالتالي دي مش أفضل طريقة .. كمان هنا فيه مشكلة بتسمى primary clustering ان ال hash values بتتجمع ورا بعض فيضطرك انك ت search بشكل linear وده بيؤدي الى ال worst case.
Quadratic probing
ال Quadratic probing هو شبه ال Linear probing ولكن القيم بتتزايد بشكل Quadratic مش Linear بالنسبة لقيمة ال i وهي بالشكل ده:
h(k, i) = (h`(k) + C1 * i + C2 * i2) mod m
هنا h` هي auxiliary hash function و C1 و C2 هما auxiliary constants .. هنا حلينا مشكلة تكتل ال items في slots ورا بعض ولكن مازال عدد ال possible permutations هو m لان مازال ال sequence بيعتمد على قيمة ال h` .. وهنا برضه بتنشأ مشكلة بنسميها ال secondary clustering وهي تكتل ال items بس مش ورا بعض.
Double Hashing
ال Double hashing هو أفضلهم لانه بيقدر ي generate عدد m2 من ال sequences وده بسبب انه بيعتمد على 2 auxiliary hash functions بالشكل ده:
h(k, i) = (h1(k) + ih2(k)) mod m
هنا h1 و h2 هما 2 auxiliary functions .. هنا فيه ميزة كويسة جدا ان الاعتماد مبقاش على auxiliary hash function واحدة بس .. لا ده اتنين .. وبالتالي علشان اتنين keys يكون ليهم نفس ال sequence لازم يكون ليهم نفس ال hash value في ال 2 functions وبالتالي الطريقة دي بتوصل لأداء أقرب لل uniform hashing.
Analysis of open-address hashing
ال analysis هنا هيعتمد على ال 𝝰 زي بالظبط ال analysis of chaining .. ال 𝝰 هي n / m و n هي عدد ال keys اللي متخزنة فال Hash table و m هي عدد ال slots الكلية بتاع ال Hash table .. باستنتاج رياضي طويل قدروا يوصلوا ان في ال average case ال Insertion وال Search ال running time هو θ(1 / 1 - 𝝰( وبالتالي كل ما ال 𝝰 تقل كل ميكون الأداء constant مش linear .. وبالتالي في حالة ال open addressing مهم ان ال m يكون أكبر من ال n بشوية علشان نوصل ل constant time ولان كل ما ال n تقرب من ال m كل مالاداء يقرب من ال linear.
Perfect hashing
ال Perfect hashing هو أي hashing ال search operation بتاخد O(1) في ال worst case .. ده ممكن تحقيقة في حالة ان ال keys ثابتة static .. زي مثلا أشهر 1000 كلمة في لغة معينة .. دي keys ثابتة مش بتتغير .. في الحالة دي فيه طريقة تقدر توصل بيها ل O(1) في ال worst case .. الطريقة بتعتمد على ال universal hashing .
الطريقة ببساطة هي استخدام 2-level hashing .. يعني هتعمل hashing في الاول لل Key ل slot معينة .. في كل slot بدل مافيه Linked List هيبقى فيه Hash table تاني هتعمل Hashing تاني فيه .. فبكدة فيه 2-level hashing .. مش بس كدة احنا هنخلي عدد ال slots بتاع ال Hash tables اللي في ال level التاني مربع عدد ال items المتخزنة فيه ال Hash table ده وبالتالي هنقدر نضمن ان فيه function في ال universal functions تقدر ت operate في ال second level ده بدون اي collisions .. وال function بنختارها لكل Hash table في ال level التاني يعني مش واحدة ثابتة دي بنختارها بحيث انها تضمن ان مفيش collisions في ال level التاني .. المشكل بتظهر في ال memory requirement لان احنا محتاجين نحجز slots عددها مربع عدد ال items اللي هنخزنها في ال level التاني .. ولكن مع اختيار function كويسة في ال level الاول تقدر تثبت رياضيا ان ال memory requirement لسة O(1) وده بسبب ان ال hash function اللي في ال level الاول بتوزعهم بشكل كويس بحيث ان تربيع العدد ده مش بيأثر أوي على ال overall needed memory requirements.
Implementation
وده implementation لل Hash table باستخدام ال division ك Hash function وال chaining ك collision resolution technique.

جزاك الله خيرا......الشرح اللهم بارك رائع ممكن شرح الفصل 22 و24 محتاجاهم ضروري بارك الله فيك
ردحذفالله يجزيك الخير,,,,,,,,,ارجو المواصلة لكن مع شرح واضافة جميع افكار وخوارزميات الكتاب
ردحذف